Methodological Development
The independent cohort studies (ICS) that comprise the ECHO-wide Cohort Study differ with respect to original study design, sampling strategy, primary outcomes of interest, and data elements collected. This results in methodological challenges related to cohort-level missing data and issues related to pooling the ICS in analyses. ECHO ICS also vary greatly by both time and place. Participants are located across the country, and some ECHO “children” were born in the 1990s while pregnant women and newborns are actively under enrollment! This introduces multiple challenges for area-level exposures as they need to be developed using nationally available data with multiple timepoints.
Research Spotlight
The Environmental influences on Child Health Outcomes (ECHO)-wide Cohort |
Knapp EA, Kress AM, Parker CB, Page GP, McArthur K, Gachigi KK, Alshawabkeh AN, Aschner JL, Bastain TM, Breton CV, Bendixsen CG, Brennan PA, Bush NR, Buss C, Camargo CA Jr, Catellier D, Cordero JF, Croen L, Dabelea D, Deoni S, D'Sa V, Duarte CS, Dunlop AL, Elliott AJ, Farzan SF, Ferrara A, Ganiban JM, Gern JE, Giardino AP, Towe-Goodman NR, Gold DR, Habre R, Hamra GB, Hartert T, Herbstman JB, Hertz-Picciotto I, Hipwell AE, Karagas MR, Karr CJ, Keenan K, Kerver JM, Koinis-Mitchell D, Lau B, Lester BM, Leve LD, Leventhal B, LeWinn KZ, Lewis J, Litonjua AA, Lyall K, Madan JC, McEvoy CT, McGrath M, Meeker JD, Miller RL, Morello-Frosch R, Neiderhiser JM, O'Connor TG, Oken E, O'Shea M, Paneth N, Porucznik CA, Sathyanarayana S, Schantz SL, Spindel ER, Stanford JB, Stroustrup A, Teitelbaum SL, Trasande L, Volk H, Wadhwa PD, Weiss ST, Woodruff TJ, Wright RJ, Zhao Q, Jacobson LP, on behalf of program collaborators for Environmental Influences On Child Health Outcomes. The Environmental influences on Child Health Outcomes (ECHO)-wide Cohort. Am J Epidemiol. 2023 Mar 24:kwad071. doi: 10.1093/aje/kwad071. Epub ahead of print. PMID: 36963379. |
Cohort-Level Missing Data
There is a wealth of extant data in the ECHO-wide Cohort, but differences in data collection methods by the ICS offer challenges. Methodological issues in harmonizing extant data occur when subject-matter experts do not recommend combining sources of data in a domain, and results in disparate covariate information in ECHO-wide analyses. This issue is not addressed well in the literature as most consortium cohort studies consist of studies with similar disease-based outcomes (e.g., Alzheimer’s, HIV) with comparable exposure and covariate data. Traditional approaches for cohort-level missing confounder data include: 1) dropping variable(s) with missing data which may lead to residual confounding bias; 2) excluding cohorts missing data elements in their entirety from the analysis, reducing the sample size, precision, and possibly generalizability; 3) and/or using traditional missing data imputation approaches. The ECHO DAC is working on novel applications of existing methodologies and developing new missing data methods using the framework presented below

| Link to full size image |
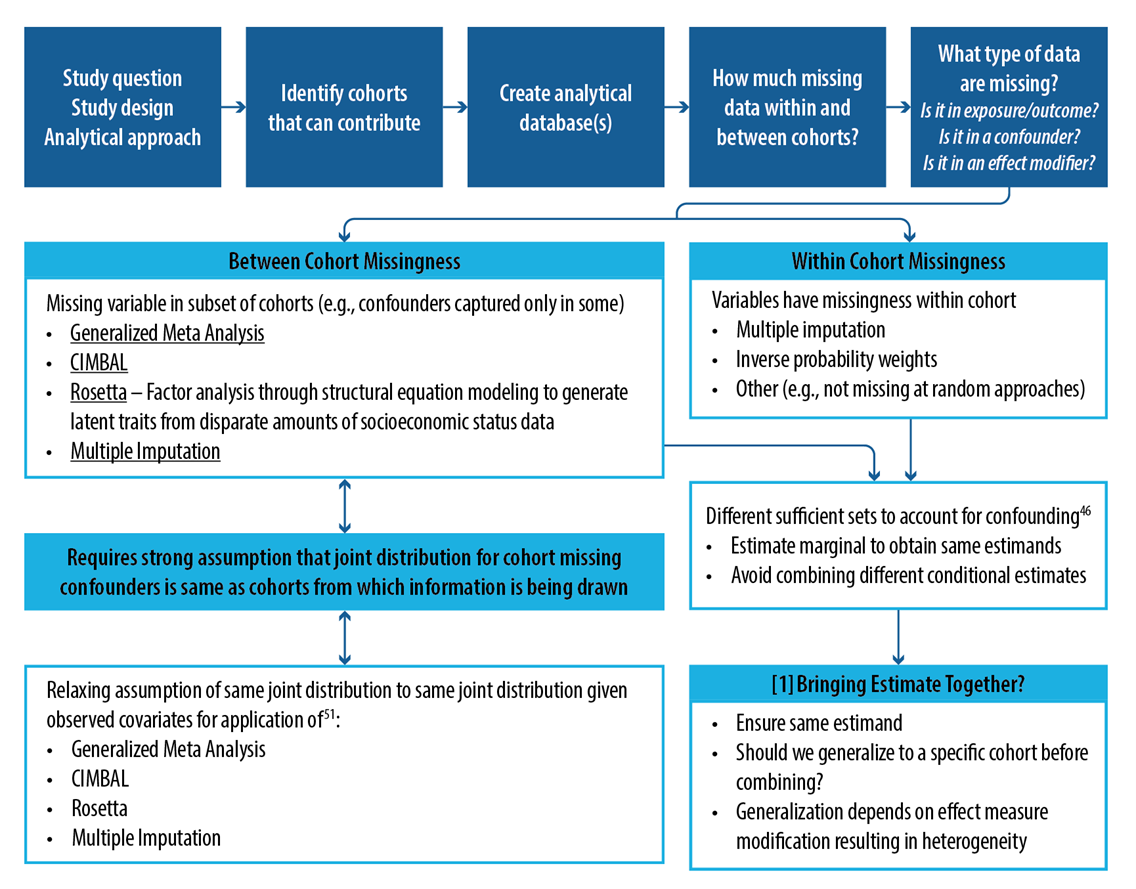{kind=link}
Sufficient Adjustment Sets
| Combining Effect Estimates Across Cohorts and Sufficient Adjustment Sets for Collaborative Research: A Simulation Study | Hamra GB, Lesko CR, Buckley JP, Jensen ET, Tancredi D, Lau B, Hertz-Picciotto I; program collaborators for Environmental influences on Child Health Outcomes. Combining Effect Estimates Across Cohorts and Sufficient Adjustment Sets for Collaborative Research: A Simulation Study. Epidemiology. 2021 May 1;32(3):421-424. doi: 10.1097/EDE.0000000000001336. PMID: 33591054; PMCID: PMC8012230.PMCID: PMC8012230 | |
| Background: Collaborative research often combines findings across multiple, independent studies via meta-analysis. Ideally, all study estimates that contribute to the meta-analysis will be equally unbiased. Many meta-analyses require all studies to measure the same covariates. We explored whether differing minimally sufficient sets of confounders identified by a directed acyclic graph (DAG) ensures comparability of individual study estimates. Our analysis applied four statistical estimators to multiple minimally sufficient adjustment sets identified in a single DAG. Methods: We compared estimates obtained via linear, log-binomial, and logistic regression and inverse probability weighting, and data were simulated based on a previously published DAG. Results: Our results show that linear, log-binomial, and inverse probability weighting estimators generally provide the same estimate of effect for different estimands that are equally sufficient to adjust confounding bias, with modest differences in random error. In contrast, logistic regression often performed poorly, with notable differences in effect estimates obtained from unique minimally sufficient adjustment sets, and larger standard errors than other estimators. Conclusions: Our findings do not support the reliance of collaborative research on logistic regression results for meta-analyses. Use of DAGs to identify potentially differing minimally sufficient adjustment sets can allow meta-analyses without requiring the exact same covariates. | ||

| Link to full size image |
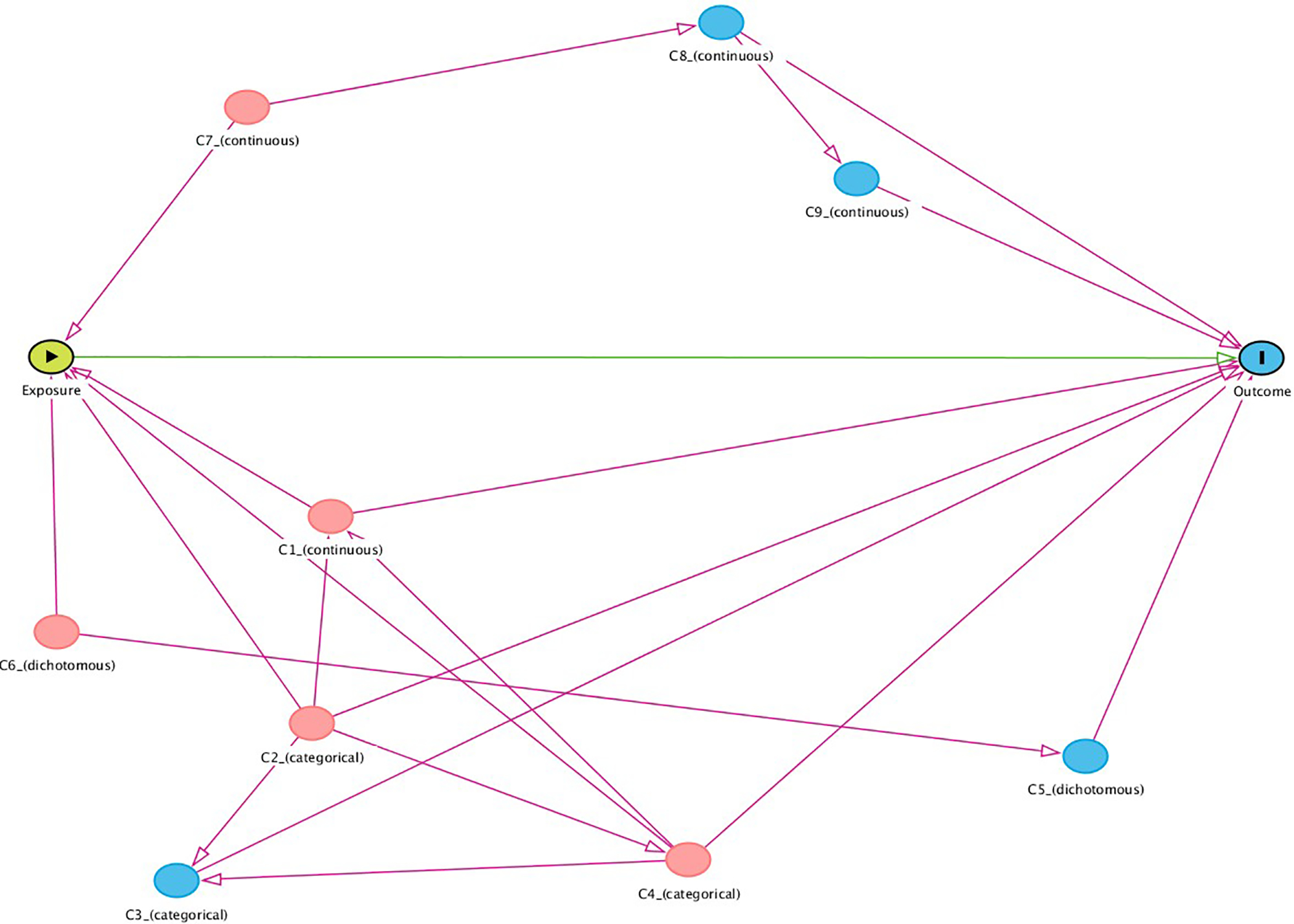{kind=link}
| Download R Code |
GENMETA
| Generalized meta-analysis for multiple regression models across studies with disparate covariate information | Kundu P, Tang R, Chatterjee N. Generalized meta-analysis for multiple regression models across studies with disparate covariate information. Biometrika. 2019 Sep;106(3):567-585. doi: 10.1093/biomet/asz030. Epub 2019 Jul 13. PMID: 31427822; PMCID: PMC6690173. | |
| Meta-analysis is widely popular for synthesizing information on common parameters of interest across multiple studies because of its logistical convenience and statistical efficiency. We develop a generalized meta-analysis approach to combining information on multivariate regression parameters across multiple studies that have varying levels of covariate information. Using algebraic relationships among regression parameters in different dimensions, we specify a set of moment equations for estimating parameters of a maximal model through information available from sets of parameter estimates for a series of reduced models from the different studies. The specification of the equations requires a reference dataset for estimating the joint distribution of the covariates. We propose to solve these equations using the generalized method of moments approach, with the optimal weighting of the equations taking into account uncertainty associated with estimates of the parameters of the reduced models. We describe extensions of the iterated reweighted least-squares algorithm for fitting generalized linear regression models using the proposed framework. Based on the same moment equations, we also develop a diagnostic test for detecting violations of underlying model assumptions, such as those arising from heterogeneity in the underlying study populations. The proposed methods are illustrated with extensive simulation studies and a real-data example involving the development of a breast cancer risk prediction model using disparate risk factor information from multiple studies. | ||
| Download GENMETA Code from GitHub | ||
CIMBAL
| Meta-analysis under imbalance in measurement of confounders in cohort studies using only summary-level data | Ray D, Muñoz A, Zhang M, Li X, Chatterjee N, Jacobson LP, Lau B. Meta-analysis under imbalance in measurement of confounders in cohort studies using only summary-level data. BMC Med Res Methodol. 2022 May 19;22(1):143. doi: 10.1186/s12874-022-01614-9. PMID: 35590267; PMCID: PMC9118777. |
BACKGROUNDCohort collaborations often require meta-analysis of exposure-outcome association estimates across cohorts as an alternative to pooling individual-level data that requires a laborious process of data harmonization on individual-level data. However, it is likely that important confounders are not all measured uniformly across the cohorts due to differences in study protocols. This imbalance in measurement of confounders leads to association estimates that are not comparable across cohorts and impedes the meta-analysis of results. METHODSIn this article, we empirically show some asymptotic relations between fully adjusted and unadjusted exposure-outcome effect estimates, and provide theoretical justification for the same. We leverage these results to obtain fully adjusted estimates for the cohorts with no information on confounders by borrowing information from cohorts with complete measurement on confounders. We implement this novel method in CIMBAL (confounder imbalance), which additionally provides a meta-analyzed estimate that appropriately accounts for the dependence between estimates arising due to borrowing of information across cohorts. We perform extensive simulation experiments to study CIMBAL’s statistical properties. We illustrate CIMBAL using National Children’s Study (NCS) data to estimate association of maternal education and low birth weight in infants, adjusting for maternal age at delivery, race/ethnicity, marital status, and income. RESULTS
Our simulation studies indicate that estimates of exposure-outcome association from CIMBAL are closer to the truth than those from commonly-used approaches for meta-analyzing cohorts with disparate confounder measurements. CIMBAL is not too sensitive to heterogeneity in underlying joint distributions of exposure, outcome and confounders but is very sensitive to heterogeneity of confounding bias across cohorts. Application of CIMBAL to NCS data for a proof-of-concept analysis further illustrates the utility and advantages of CIMBAL. Link to full size image. CONCLUSIONSCIMBAL provides a practical approach for meta-analyzing cohorts with imbalance in measurement of confounders under a weak assumption that the cohorts are independently sampled from populations with the same confounding bias. | |
| Download the CIMBAL R program from GitHub here | |
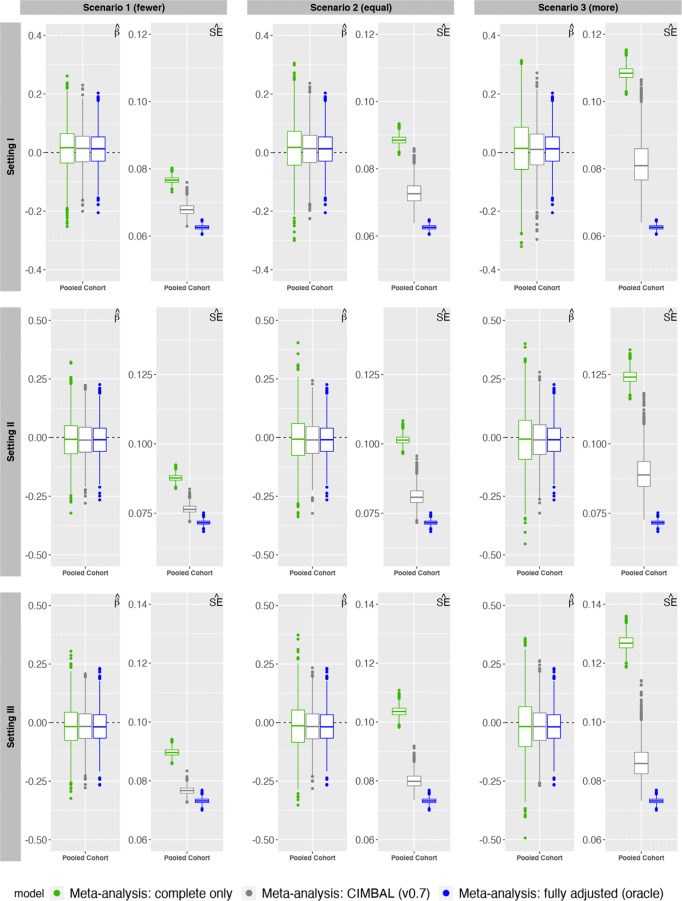{kind=link}
Machine Learning Methods to Identify Cohorts with Similar Joint Distributions
| Machine Learning Methods to Identify Cohorts with Similar Joint Distributions | Smirnova, E., Zhong, Y., Alsaadawi, R., Ning, X., Kress, A., Kuiper, J., ... & Lau, B. (2022). Missing data interpolation in integrative multi-cohort analysis with disparate covariate information. arXiv preprint arXiv:2211.00407. |
Drs. Lau and Smirnova have developed new methods to impute cohort-level missing data. Existing methods for dealing with disparate covariate data across cohorts, (e.g., generalized meta-analysis) assume that the underlying joint distributions are the same. This assumption is difficult to test and may be violated. They developed a machine learning approach, combining unsupervised random forests to obtain distances between observations within and across cohorts, hierarchical clustering to identify sub-groups of cohorts, and then tested whether covariate distributions provide evidence differences in joint distributions. The performance of these methods was tested using an extensive set of simulations which indicated that the algorithm correctly identifies the cohort subgroups.
| Download RELATE R Package from GitHub |
| Watch Dr. Lau’s ECHO Discovery Series Presentation HERE |
| Research was presented at SER and JSM in Summer 2022! |
| Paper available here |
Rosetta
| A Latent Trait-based Measure as a Data Harmonization and Missing Data Solution Applied to the Environmental Influences on Child Health Outcomes Cohort | Knapp, E. A., Kress, A. M., Ghidey, R., Gorham, T. J., Galdo, B., Petrill, S. A., Aris, I. M., Bastain, T. M., Camargo, C. A., Jr, Coccia, M. A., Cragoe, N., Dabelea, D., Dunlop, A. L., Gebretsadik, T., Hartert, T., Hipwell, A. E., Johnson, C. C., Karagas, M. R., LeWinn, K. Z., Maldonado, L. E., … program collaborators for Environmental influences on Child Health Outcomes* (2025). A Latent Trait-based Measure as a Data Harmonization and Missing Data Solution Applied to the Environmental Influences on Child Health Outcomes Cohort. Epidemiology (Cambridge, Mass.), 10.1097/EDE.0000000000001832. Advance online publication. https://doi.org/10.1097/EDE.0000000000001832 |
The DAC (Drs. Lau, Knapp, and Kress) worked with Drs. Christopher Bartlett and Stephen Petrill (affiliated with the Family Life project, to use their novel Rosetta approach, which is a method that is highly related to linear algebra for factor analysis through structural equation modeling with the goal of creating latent traits to combine cohorts with disparate amounts of socioeconomic status data.
| Paper available here |
Combining Cohorts
Combining Independent Cohort Studies in Collaborative Studies
One of the main goals of the ECHO-wide cohort is to conduct large population-level analyses by integrating data from multiple independent cohort study (ICS). However, pooling data from the heterogenous study populations of the 69 ICS is methodologically challenging. Each ECHO ICS has its own unique sample and target population(s), research question, geography, calendar year(s) of data collection, and potentially increased risk of specific outcome(s) or exposure(s). For a given analysis, these cohort-level effects should be evaluated and either included in the primary analyses and/or addressed with sensitivity analyses.
Collaborative, Pooled, and Harmonized Study Designs Combining Independent Cohort Studies in Collaborative Studies
Collaborative, Pooled, and Harmonized Study Designs Combining Independent Cohort Studies in Collaborative Studies
| Collaborative, pooled and harmonized study designs for epidemiologic research: challenges and opportunities | Catherine R Lesko, Lisa P Jacobson, Keri N Althoff, Alison G Abraham, Stephen J Gange, Richard D Moore, Sharada Modur, Bryan Lau. Collaborative, pooled and harmonized study designs for epidemiologic research: challenges and opportunities. International Journal of Epidemiology, Volume 47, Issue 2, April 2018, Pages 654–668, https://doi.org/10.1093/ije/dyx283 |
| Collaborative study designs (CSDs) that combine individual-level data from multiple independent contributing studies (ICSs) are becoming much more common due to their many advantages: increased statistical power through large sample sizes; increased ability to investigate effect heterogeneity due to diversity of participants; cost-efficiency through capitalizing on existing data; and ability to foster cooperative research and training of junior investigators. CSDs also present surmountable political, logistical and methodological challenges. Data harmonization may result in a reduced set of common data elements, but opportunities exist to leverage heterogeneous data across ICSs to investigate measurement error and residual confounding. Combining data from different study designs is an art, which motivates methods development. Diverse study samples, both across and within ICSs, prompt questions about the generalizability of results from CSDs. However, CSDs present unique opportunities to describe population health across person, place and time in a consistent fashion, and to explicitly generalize results to target populations of public health interest. Additional analytic challenges exist when analysing CSD data, because mechanisms by which systematic biases (e.g. information bias, confounding bias) arise may vary across ICSs, but multidisciplinary research teams are ready to tackle these challenges. CSDs are a powerful tool that, when properly harnessed, permits research that was not previously possible | |
Cohort Heterogeneity
Drs. Zhong, Lau, and Stuart are examining cohort heterogeneity and implications for combining cohorts. Cohort consortia are collaborative study designs that aim to achieve a similar research goal by combining individual cohorts. Pooled analysis using cohort consortium data holds several major benefits, including increased sample size, and possibly increased generalizability. However, across-cohort heterogeneity can be a major challenge when using data sourced from different studies, with a key question being when it is appropriate to combine cohorts for a specific research question, and when they are too different for reliable combining. We formalize the concept of cohort heterogeneity in the context of cohort consortia, define three types of cohort heterogeneity, and discuss the implications of cohort heterogeneity as applied to the diverse goals of epidemiologic research. Understanding cohort heterogeneity facilitates investigators to identify and minimize biases that may occur in pooled analysis.
Guide for Including Cohort Effects in Analyses
Drs. Knapp and Kress are working on step-by-step recommendations for evaluating cohort-level clustering, including cohort-effects in models, and conducting sensitivity analyses.
The Environmental influences on Child Health Outcomes (ECHO)-wide Cohort |
| Knapp EA, Kress AM, Parker CB, Page GP, McArthur K, Gachigi KK, Alshawabkeh AN, Aschner JL, Bastain TM, Breton CV, Bendixsen CG, Brennan PA, Bush NR, Buss C, Camargo CA Jr, Catellier D, Cordero JF, Croen L, Dabelea D, Deoni S, D'Sa V, Duarte CS, Dunlop AL, Elliott AJ, Farzan SF, Ferrara A, Ganiban JM, Gern JE, Giardino AP, Towe-Goodman NR, Gold DR, Habre R, Hamra GB, Hartert T, Herbstman JB, Hertz-Picciotto I, Hipwell AE, Karagas MR, Karr CJ, Keenan K, Kerver JM, Koinis-Mitchell D, Lau B, Lester BM, Leve LD, Leventhal B, LeWinn KZ, Lewis J, Litonjua AA, Lyall K, Madan JC, McEvoy CT, McGrath M, Meeker JD, Miller RL, Morello-Frosch R, Neiderhiser JM, O'Connor TG, Oken E, O'Shea M, Paneth N, Porucznik CA, Sathyanarayana S, Schantz SL, Spindel ER, Stanford JB, Stroustrup A, Teitelbaum SL, Trasande L, Volk H, Wadhwa PD, Weiss ST, Woodruff TJ, Wright RJ, Zhao Q, Jacobson LP, on behalf of program collaborators for Environmental Influences On Child Health Outcomes. The Environmental influences on Child Health Outcomes (ECHO)-wide Cohort. Am J Epidemiol. 2023 Mar 24:kwad071. doi: 10.1093/aje/kwad071. Epub ahead of print. PMID: 36963379. |